大数据概述
大数据
两个方面
数据体积
bit,byte,kb,mb,gb,tb,pb,eb,zb,nb,db,yb
处理方式
存储问题
数据体积比较大的时候不适合进行集中式的存储,转而使用分布式的存储
集中式存储
一个完整的数据都存储在一个存储介质中,数据的物理结构没有被破坏,是完整的,
比如一个100mb的数据存放在一块1t的硬盘中
分布式存储
一个完整的数据存储在不同的存储介质中,数据的物理结构被破坏了,从逻辑上看同样是完整,
比如一个100mb的数据,其中50mb存放在A机器,30m存放在b机器,20mb存放在c机器
为了保证数据的健壮性,我们需要对数据做冗余存储(备份),把这种存储方式称之为分布式存储
计算问题
集中式计算
计算和数据在同一个机器的,同一个进程中完成。
分布式计算
1+。。。+1000=50500 一台机器计算需要10分钟
机器A:1+。。。+100=A 1分钟
机器B:101+。。。+200=B
机器i:。。。
机器Z:901+。。。+100=Z
最终将机器A,B,i,。。,Z计算的结果汇总到其中的一台机器中,最后得到需要的结果。
也就是说将一个完整的计算拆分中若干个子模块进行计算,将子模块计算的结果,
最终进行汇总得到最终结果的计算,称之为分布式计算。
描述大数据的时候,需要从两个方面来说
数据大
使用非常规的技术/软件去存储和计算这些体积海量数据
Hadoop概述
Hadoop基本概述
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
简言之:Hadoop是适合海量数据的分布式存储和分布式计算平台。受Google三篇论文启发,由作者Doug Cutting开发出来的。
问: 为什么hdfs不适合存储小文件?
假如有一个100m的文件和100个1m的文件,在数据存储上面完全没有任何差异;但是在管理节点或者元数据管理上面,
一个100m的文件只有一份 元数据信息,而这100个1m文件的元数据信息就有100分,会对管理节点造成非常大的存储
压力,所以不建议或不适合存储大量的小文件。
分布式存储与分布式计算
分布式存储
在分布式存储系统中,分散在不同节点中的数据可能属于同一
个文件,为了组织众多的文件,把文件可以放到不同的文件夹中,
文件夹可以一级一级的包含。我们把这种组织形式称为命名空间
(namespace)。命名空间管理着整个服务器集群中的所有文件。
分布式计算
把一个需要非常巨大的计算能力才能解决的问题分成许多小的
部分,然后把这些部分分配给许多计算机进行处理,最后把这些计
算结果综合起来得到最终的结果。
Hadoop四大模块
Hadoop Common: The common utilities that support the other Hadoop modules.
Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
Hadoop YARN: A framework for job scheduling and cluster resource management.
Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.hdfs1中的管理节点有单点故障问题
Hadoop各个核心项目架构
HDFS2的架构
负责对数据的分布式存储,主从结构
主节点——namenode
可以有2个,负责内容:
1)接收用户的请求操作,是用户操作的入口
2)维护文件系统的目录结构,称为命名空间
从节点——datanode(存储节点)
至少一个,只干一件事:存储数据
Yarn的架构
是一个资源的调度和管理平台,也是主从结构
主节点——ResourceManager
可以有2个,主要负责:
1)集群资源的分配和调度
2)MR、Storm、Spark等应用,要想被RM管理,必须实现ApplicationMaster接口
从节点——NodeManager(计算节点)
可以有多个,主要就是单节点资源的管理。
MapReduce的架构
依赖于磁盘IO的批处理计算模型,只有一个主节点——MRAppMaster,主要负责:
1)接收客户端提交的计算任务
2)把计算任务分给NodeManager中的Container执行,即任务调度
3)监控Task的执行情况
数据和计算之间的距离,称之为数据或计算本地性
Hadoop单机版安装
CentOS的配置
1、网卡:NAT
网络:192.168.43.101
NetMask:255.255.255.0
GateWay:192.168.43.2
DNS Server:124.207.160.106,219.239.26.42
配置完毕之后,重启网卡:
]#service network restart
2、修改主机名和ip地址映射文件(重启生效)
vim /etc/sysconfig/network
将HOSTNAME改为uplooking01
保存退出:
vim /etc/hosts
加入一行内容:
192.168.43.101 uplooking01
同样在windows下面也做相同的映射配置(C:\Windows\System32\drivers\etc\hosts):
3、关闭防火墙,并从开机启动项中去处防火墙
关闭防火墙:
service iptables stop
从开机启动项中移除防火墙
chkconfig iptables off
4、关闭selinux服务(重启生效)
vim /etc/selinux/config
SELINUX=disabled
5、开启最小多用户模式
vim /etc/inittab
id:5:initdefault:--->id:3:initdefault:
在CentOS下面安装软件的一些约定:
所有的软件上传至/home/uplooking/soft
安装在/home/uplooking/app目录
如果在命令中出现[]表示可选,<>表示必须
使用xftp软件将jdk和hadoop安装压缩包上传至/opt/soft目录下,进行安装:
1、安装JDK
第一步:解压
opt]# tar -zxvf /opt/soft/jdk-8u112-linux-x64.tar.gz [-C /opt/]
第二步:重命名
opt]# mv jdk1.8.0_112/ jdk
第三步:配置JAVA_HOME环境变量
vim /etc/profile.d/hadoop-etc.sh,添加一下内容
export JAVA_HOME=/opt/jdk
export PATH=$PATH:$JAVA_HOME/bin
保存退出,并让环境生效
source /etc/profile.d/hadoop-etc.sh
第四步:验证
java -version
2、Hadoop的安装/home/uplooking/app目录
hadoop的版本:hadoop-2.6.4.tar.gz
1°、解压:
[uplooking@uplooking01 ~]$ tar -zxvf soft/hadoop-2.6.4.tar.gz -C /home/uplooking/app/
2°、重命名:
[uplooking@uplooking01 ~]$ mv /home/uplooking/app/hadoop-2.6.4/ /home/uplooking/app/hadoop
3°、添加hadoop相关命令到环境变量中
~]$ vim ~/.bash_profile
加入以下内容:
export HADOOP_HOME=/home/uplooking/app/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
生效:
~]$ source ~/.bash_profile
4°、创建数据存储目录:
1) NameNode 数据存放目录: /home/uplooking/data/hadoop/name
2) SecondaryNameNode 数据存放目录: /home/uplooking/data/hadoop/secondary
3) DataNode 数据存放目录: /home/uplooking/data/hadoop/data
4) 临时数据存放目录: /home/uplooking/data/hadoop/tmp
5°、配置 hadoop-env.sh 、yarn-env.sh hdfs-site.xml core-site.xml mappred-site.xml yarn-site.xml
1)、配置hadoop-env.sh
export JAVA_HOME=/opt/jdk
2)、配置yarn-env.sh
export JAVA_HOME=/opt/jdk
3)、配置hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/uplooking/data/hadoop/name</value>
<description>存放元数据的磁盘目录</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/uplooking/data/hadoop/data</value>
<description>存放数据的磁盘目录</description>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/home/uplooking/data/hadoop/secondary</value>
<description>存放检查点数据的磁盘目录</description>
</property>
<!-- secondaryName http地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>uplooking01:9001</value>
</property>
<!-- 数据备份数量-->
<property>
<name>dfs.replication</name>
<value>1</value>
<description>默认有3分,但是目前只有一台机器,所以备份数设置为1</description>
</property>
<!-- 运行通过web访问hdfs-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!-- 剔除权限控制-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
4)、配置core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://uplooking01:9000</value>
<description>hdfs内部通讯访问地址</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/uplooking/data/hadoop/tmp</value>
</property>
</configuration>
5)、配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史job的访问地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>uplooking01:10020</value>
</property>
<!-- 历史job的访问web地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>uplooking01:19888</value>
</property>
<property>
<name>mapreduce.map.log.level</name>
<value>INFO</value>
</property>
<property>
<name>mapreduce.reduce.log.level</name>
<value>INFO</value>
</property>
</configuration>
6)、配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>uplooking01</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>uplooking01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>uplooking01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>uplooking01:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>uplooking01:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>uplooking01:8088</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
</configuration>
格式化hadoop文件系统
hdfs namenode -format
当出现Storage directory /home/uplooking/data/hadoop/name has been successfully formatted.则说明格式化成功
负责失败,如果失败的话:就要检查配置文件,再次进行格式化,如果要再次进行格式化,
必须要把dfs.namenode.name.dir配置目录下面的数据清空。
启动hadoop
start-all.sh
分为以下
start-dfs.sh
start-yarn.sh
启动成功之后,通过java命令jps(java process status)会出现5个进程:
NameNode
SecondaryNameNode
DataNode
ResourceManager
NodeManager
在启动的时候,提示需要输入的密码,是因为没有配置ssh免密码登录模式,如何配置?
ssh-keygen -t rsa
一路回车
ssh-copy-id -i uplooking@uplooking01
根据提示输入当前机器的密码
验证:ssh uplooking@uplooking01 不需要再输入密码
验证:
1°、在命令中执行以下命令:
hdfs dfs -ls /
2°、在浏览器中输入http://uplooking01:50070
3°、验证mr
/home/uplooking/app/hadoop/share/hadoop/mapreduce目录下面,执行如下命令:
--------下面是个人添加的笔记--------
hdfs dfs -mkdir -p /wordcount/input
mkdir dfs -mkdir -p /wordcount/output
hdfs dfs -put word.txt /wordcount/input
--------上面是个人添加的笔记--------
yarn jar hadoop-mapreduce-examples-2.6.4.jar wordcount /hello /out
在执行作业的过程中,也可以在地址栏中输入:http://uplooking01:8088来查看作业的执行状态
问题:
如果要进行多次格式化,那么需要将刚才创建的/home/uplooking/data/hadoop/中的文件夹删除重建,
才能进行二次格式化
另外,如果后面向hadoop提交mr项目时,如果想查看输出,可以参考下面的方法:
yarn-site.xml中配置:
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
重启yarn和historyserver
执行sbin/mr-jobhistory-daemon.sh start historyserver


 Asynq任务框架
Asynq任务框架 MCP智能体开发实战
MCP智能体开发实战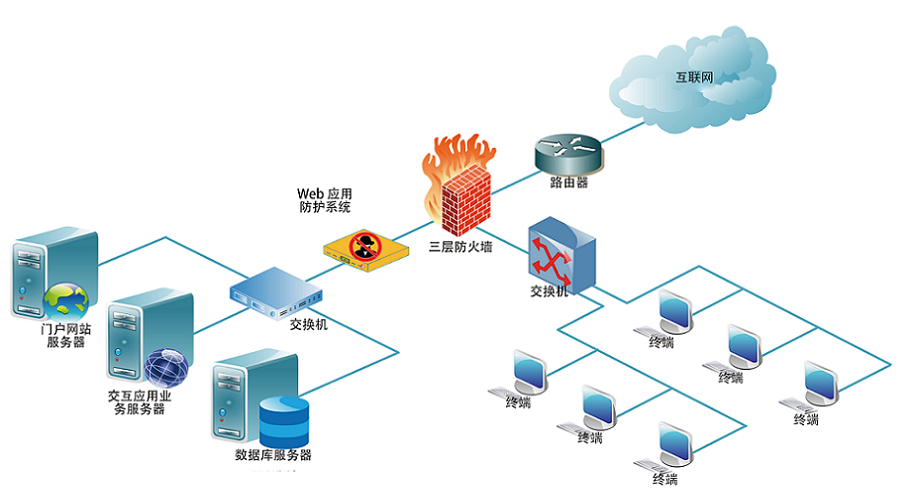 WEB架构
WEB架构 安全监控体系
安全监控体系