概述
如果RabbitMQ集群只有一个broker节点,那么该节点的失效将导致整个服务临时性的不可用,并且可能会导致message的丢失(尤其是在非持久化message存储于非持久化queue中的时候)。当然可以将所有的publish的message都设置为持久化的,并且使用持久化的queue,但是这样仍然无法避免由于缓存导致的问题:因为message在发送之后和被写入磁盘并执行fsync之间存在一个虽然短暂但是会产生问题的时间窗。通过publisher的confirm机制能够确保客户端知道哪些message已经存入磁盘,尽管如此,一般不希望遇到因单点故障导致的服务不可用。
如果RabbitMQ集群是由多个broker节点构成的,那么从服务的整体可用性上来讲,该集群对于单点失效是有弹性的,但是同时也需要注意:尽管exchange和binding能够在单点失效问题上幸免于难,但是queue和其上持有的message却不行,这是因为queue及其内容仅仅存储于单个节点之上,所以一个节点的失效表现为其对应的queue不可用。
引入RabbitMQ的镜像队列机制,将queue镜像到cluster中其他的节点之上。在该实现下,如果集群中的一个节点失效了,queue能自动地切换到镜像中的另一个节点以保证服务的可用性。在通常的用法中,针对每一个镜像队列都包含一个master和多个slave,分别对应于不同的节点。slave会准确地按照master执行命令的顺序进行命令执行,故slave与master上维护的状态应该是相同的。除了publish外所有动作都只会向master发送,然后由master将命令执行的结果广播给slave们,故看似从镜像队列中的消费操作实际上是在master上执行的。
一旦完成了选中的slave被提升为master的动作,发送到镜像队列的message将不会再丢失:publish到镜像队列的所有消息总是被直接publish到master和所有的slave之上。这样一旦master失效了,message仍然可以继续发送到其他slave上。
RabbitMQ的镜像队列同时支持publisher confirm和事务两种机制。在事务机制中,只有当前事务在全部镜像queue中执行之后,客户端才会收到Tx.CommitOk的消息。同样的,在publisher confirm机制中,向publisher进行当前message确认的前提是该message被全部镜像所接受了。
镜像队列的设置
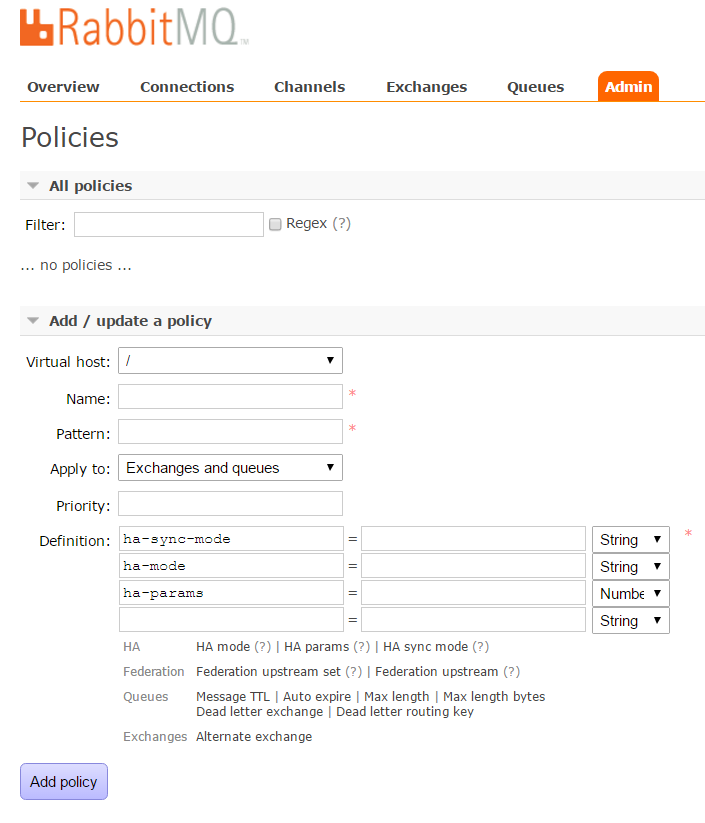
镜像队列的配置通过添加policy完成,policy添加的命令为:
rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]
-p Vhost: 可选参数,针对指定vhost下的queue进行设置
Name: policy的名称
Pattern: queue的匹配模式(正则表达式)
Definition:镜像定义,包括三个部分ha-mode, ha-params, ha-sync-mode
ha-mode:指明镜像队列的模式,有效值为 all/exactly/nodes
all:表示在集群中所有的节点上进行镜像
exactly:表示在指定个数的节点上进行镜像,节点的个数由ha-params指定
nodes:表示在指定的节点上进行镜像,节点名称通过ha-params指定
ha-params:ha-mode模式需要用到的参数
ha-sync-mode:进行队列中消息的同步方式,有效值为automatic和manual
priority:可选参数,policy的优先级例如,对队列名称以“queue_”开头的所有队列进行镜像,并在集群的两个节点上完成进行,policy的设置命令为:
rabbitmqctl set_policy --priority 0 --apply-to queues mirror_queue "^queue_" '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'也可以通过RabbitMQ的web管理界面设置:
镜像队列的原理
普通MQ的结构
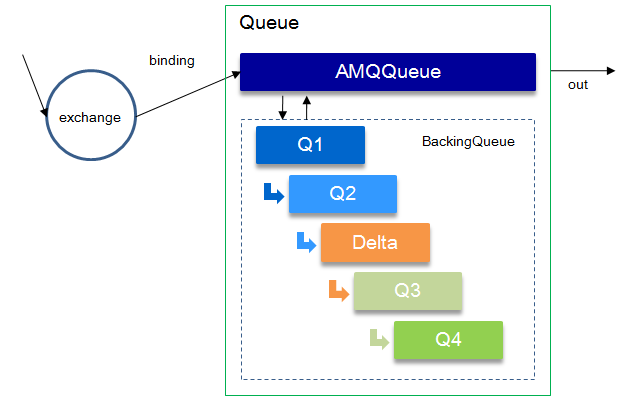
通常队列由两部分组成:一部分是AMQQueue,负责AMQP协议相关的消息处理,即接收生产者发布的消息、向消费者投递消息、处理消息confirm、acknowledge等等;另一部分是BackingQueue,它提供了相关的接口供AMQQueue调用,完成消息的存储以及可能的持久化工作等。
在RabbitMQ中BackingQueue又由5个子队列组成:Q1, Q2, Delta, Q3和Q4。RabbitMQ中的消息一旦进入队列,不是固定不变的,它会随着系统的负载在队列中不断流动,消息的不断发生变化。与这5个子队列对于,在BackingQueue中消息的生命周期分为4个状态:
- Alpha:消息的内容和消息索引都在RAM中。Q1和Q4的状态。
- Beta:消息的内容保存在DISK上,消息索引保存在RAM中。Q2和Q3的状态。
- Gamma:消息内容保存在DISK上,消息索引在DISK和RAM都有。Q2和Q3的状态。
- Delta:消息内容和索引都在DISK上。Delta的状态。
注意:对于持久化的消息,消息内容和消息所有都必须先保存在DISK上,才会处于上述状态中的一种,而Gamma状态的消息是只有持久化的消息才会有的状态。
上述就是RabbitMQ的多层队列结构的设计,我们可以看出从Q1到Q4,基本经历RAM->DISK->RAM这样的过程。这样设计的好处是:当队列负载很高的情况下,能够通过将一部分消息由磁盘保存来节省内存空间,当负载降低的时候,这部分消息又渐渐回到内存,被消费者获取,使得整个队列具有很好的弹性。下面我们就来看一下,整个消息队列的工作流程。
引起消息流动主要有两方面因素:其一是消费者获取消息;其二是由于内存不足引起消息换出到磁盘。RabbitMQ在系统运行时会根据消息传输的速度计算一个当前内存中能够保存的最大消息数量(Target_RAM_Count),当内存中的消息数量大于该值时,就会引起消息的流动。进入队列的消息,一般会按照Q1->Q2->Delta->Q3->Q4的顺序进行流动,但是并不是每条消息都一定会经历所有的状态,这个取决于当前系统的负载状况。
当消费者获取消息时,首先会从Q4队列中获取消息,如果Q4获取成功,则返回。如果Q4为空,则尝试从Q3获取消息,首先系统会判断Q3是否为空,如果为空则返回队列为空,即此时队列中无消息(后续会论证)。如果不为空,则取出Q3的消息,然后判断此时Q3和Delta队列的长度,如果都为空,则可认为Q2、Delta、Q3、Q4全部为空(后续会论证),此时将Q1中消息直接转移到Q4中,下次直接从Q4中获取消息。如果Q3为空,Delta不为空,则将Delta转移到Q3中,如果Q3不为空,则直接下次从Q3中获取消息。在将Delta转移到Q3的过程中,RabbitMQ是按照索引分段读取的,首先读取某一段,直到读到的消息非空为止,然后判断读取的消息个数与Delta中的消息个数是否相等,如果相等,则断定此时Delta中已无消息,则直接将Q2和刚读到的消息一并放入Q3中。如果不相等,则仅将此次读取到的消息转移到Q3。这就是消费者引起的消息流动过程。
消息换出的条件是内存中保存的消息数量+等待ACK的消息的数量>Target_RAM_Count。当条件出发时,系统首先会判断如果当前进入等待ACK的消息的速度大于进入队列的消息的速度时,会先处理等待ACK的消息。
最后我们来分析一下前面遗留的两个问题,一个是为什么Q3队列为空即可以认定整个队列为空。试想如果Q3为空,Delta不空,则在Q3取出最后一条消息时,Delta上的消息就会被转移到Q3上,Q3空矛盾。如果Q2不空,则在Q3取出最后一条消息,如果Delta为空,则会将Q2的消息并入到Q3,与Q3为空矛盾。如果Q1不为空,则在Q3取出最后一条消息,如果Delta和Q3均为空时,则将Q1的消息转移到Q4中,与Q4为空矛盾。这也解释了另外一个问题,即为什么Q3和Delta为空,Q2就为空。
通常在负载正常时,如果消息被消费的速度不小于接收新消息的速度,对于不需要保证可靠不丢的消息极可能只会有Alpha状态。对于durable=true的消息,它一定会进入gamma状态,若开启publish confirm机制,只有到了这个阶段才会确认该消息已经被接受,若消息消费速度足够快,内存也充足,这些消息也不会继续走到下一状态。
通常在系统负载较高时,已接受到的消息若不能很快被消费掉,这些消息就会进入到很深的队列中去,增加处理每个消息的平均开销。因为要花更多的时间和资源处理“积压”的消息,所以用于处理新来的消息的能力就会降低,使得后来的消息又被积压进入很深的队列,继续加大处理每个消息的平均开销,这样情况就会越来越恶化,使得系统的处理能力大大降低。
根据官网资料,应对这一问题,有三个措施:
- 进行流量控制。
- 增加prefetch的值,即一次发送多个消息给接收者,加快消息被消费掉的速度。
- 采用multiple ack,降低处理ack带来的开销。
镜像队列的结构
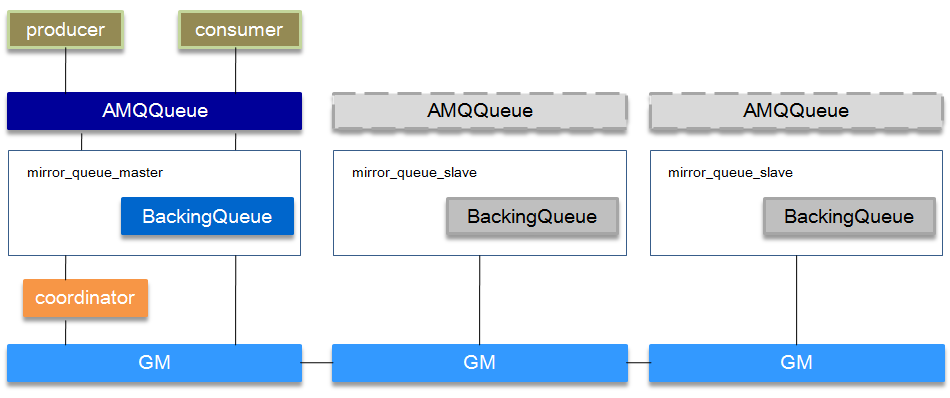
镜像队列基本上就是一个特殊的BackingQueue,它内部包裹了一个普通的BackingQueue做本地消息持久化处理,在此基础上增加了将消息和ack复制到所有镜像的功能。所有对mirror_queue_master的操作,会通过组播GM(下面会讲到)的方式同步到各slave节点。GM负责消息的广播,mirror_queue_slave负责回调处理,而master上的回调处理是由coordinator负责完成。mirror_queue_slave中包含了普通的BackingQueue进行消息的存储,master节点中BackingQueue包含在mirror_queue_master中由AMQQueue进行调用。
消息的发布(除了Basic.Publish之外)与消费都是通过master节点完成。master节点对消息进行处理的同时将消息的处理动作通过GM广播给所有的slave节点,slave节点的GM收到消息后,通过回调交由mirror_queue_slave进行实际的处理。
对于Basic.Publish,消息同时发送到master和所有slave上,如果此时master宕掉了,消息还发送slave上,这样当slave提升为master的时候消息也不会丢失。
GM, Guarenteed Multicast. GM模块实现的一种可靠的组播通讯协议,该协议能够保证组播消息的原子性,即保证组中活着的节点要么都收到消息要么都收不到。它的实现大致如下:
将所有的节点形成一个循环链表,每个节点都会监控位于自己左右两边的节点,当有节点新增时,相邻的节点保证当前广播的消息会复制到新的节点上;当有节点失效时,相邻的节点会接管保证本次广播的消息会复制到所有的节点。在master节点和slave节点上的这些gm形成一个group,group(gm_group)的信息会记录在mnesia中。不同的镜像队列形成不同的group。消息从master节点对于的gm发出后,顺着链表依次传送到所有的节点,由于所有节点组成一个循环链表,master节点对应的gm最终会收到自己发送的消息,这个时候master节点就知道消息已经复制到所有的slave节点了。
新增节点
新节点的加入过程如下图所示:
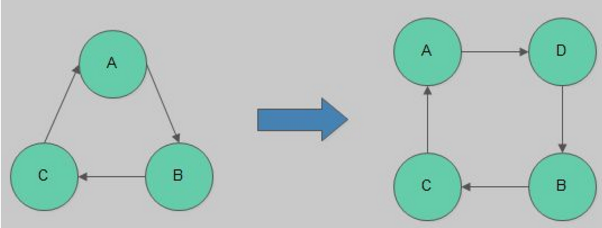
每当一个节点加入或者重新加入(例如从网络分区中恢复过来)镜像队列,之前保存的队列内容会被清空。
节点的失效
如果某个slave失效了,系统处理做些记录外几乎啥都不做:master依旧是master,客户端不需要采取任何行动,或者被通知slave失效。
如果master失效了,那么slave中的一个必须被选中为master。被选中作为新的master的slave通常是最老的那个,因为最老的slave与前任master之间的同步状态应该是最好的。然而,需要注意的是,如果存在没有任何一个slave与master完全同步的情况,那么前任master中未被同步的消息将会丢失。
消息的同步
将新节点加入已存在的镜像队列是,默认情况下ha-sync-mode=manual,镜像队列中的消息不会主动同步到新节点,除非显式调用同步命令。当调用同步命令后,队列开始阻塞,无法对其进行操作,直到同步完毕。当ha-sync-mode=automatic时,新加入节点时会默认同步已知的镜像队列。由于同步过程的限制,所以不建议在生产的active队列(有生产消费消息)中操作。
可以使用下面的命令来查看那些slaves已经完成同步:
rabbitmqctl list_queues name slave_pids synchronised_slave_pids可以通过手动的方式同步一个queue:
rabbitmqctl sync_queue name同样也可以取消某个queue的同步功能:
rabbitmqctl cancel_sync_queue name当然这些都可以通过management插件来设置。
补充要点
镜像队列不能作为负载均衡使用,因为每个操作在所有节点都要做一遍。
ha-mode参数和durable declare对exclusive队列都并不生效,因为exclusive队列是连接独占的,当连接断开,队列自动删除。所以实际上这两个参数对exclusive队列没有意义。
当所有slave都出在(与master)未同步状态时,并且ha-promote-on-shutdown设置为when-synced(默认)时,如果master因为主动的原因停掉,比如是通过rabbitmqctl stop命令停止或者优雅关闭OS,那么slave不会接管master,也就是此时镜像队列不可用;但是如果master因为被动原因停掉,比如VM或者OS crash了,那么slave会接管master。这个配置项隐含的价值取向是保证消息可靠不丢失,放弃可用性。如果ha-promote-on-shutdown设置为always,那么不论master因为何种原因停止,slave都会接管master,优先保证可用性。
镜像队列中最后一个停止的节点会是master,启动顺序必须是master先启动,如果slave先启动,它会有30s的等待时间,等待master的启动,然后加入cluster中(如果30s内master没有启动,slave会自动停止)。当所有节点因故(断电等)同时离线时,每个节点都认为自己不是最后一个停止的节点。要恢复镜像队列,可以尝试在30s之内启动所有节点。
对于镜像队列,客户端Basic.Publish操作会同步到所有节点(消息同时发送到master和所有slave上,如果此时master宕掉了,消息还发送slave上,这样当slave提升为master的时候消息也不会丢失),而其他操作则是通过master中转,再由master将操作作用于slave。比如一个Basic.Get操作,假如客户端与slave建立了TCP连接,首先是slave将Basic.Get请求发送至master,由master备好数据,返回至slave,投递给消费者。
当slave宕掉了,除了与slave相连的客户端连接全部断开之外,没有其他影响。
当master宕掉时,会有以下连锁反应:
- 与master相连的客户端连接全部断开;
- 选举最老的slave节点为master。若此时所有slave处于未同步状态,则未同步部分消息丢失;
- 新的master节点requeue所有unack消息,因为这个新节点无法区分这些unack消息是否已经到达客户端,亦或是ack消息丢失在老的master的链路上,亦或者是丢在master组播ack消息到所有slave的链路上。所以处于消息可靠性的考虑,requeue所有unack的消息。此时客户端可能有重复消息;
- 如果客户端连着slave,并且Basic.Consume消费时指定了x-cancel-on-ha-failover参数,那么客户端会受到一个Consumer Cancellation Notification通知,Java SDK中会回调Consumer接口的handleCancel方法,故需覆盖此方法。如果未指定x-cancal-on-ha-failover参数,那么消费者就无法感知master宕机,会一直等待下去。
Channel channel = ...;
Consumer consumer = ...;
Map<String, Object> args = new HashMap<String, Object>();
args.put("x-cancel-on-ha-failover", true);
channel.basicConsume("my-queue", false, args, consumer);镜像队列的恢复
前提:两个节点A和B组成以镜像队列。
场景1:A先停,B后停
该场景下B是master,只要先启动B,再启动A即可。或者先启动A,再在30s之内启动B即可恢复镜像队列。(如果没有在30s内回复B,那么A自己就停掉自己)
场景2:A,B同时停
该场景下可能是由掉电等原因造成,只需在30s内联系启动A和B即可恢复镜像队列。
场景3:A先停,B后停,且A无法恢复。
因为B是master,所以等B起来后,在B节点上调用rabbitmqctl forget_cluster_node A以接触A的cluster关系,再将新的slave节点加入B即可重新恢复镜像队列。
场景4:A先停,B后停,且B无法恢复
该场景比较难处理,旧版本的RabbitMQ没有有效的解决办法,在现在的版本中,因为B是master,所以直接启动A是不行的,当A无法启动时,也就没版本在A节点上调用rabbitmqctl forget_cluster_node B了,新版本中forget_cluster_node支持-offline参数,offline参数允许rabbitmqctl在离线节点上执行forget_cluster_node命令,迫使RabbitMQ在未启动的slave节点中选择一个作为master。当在A节点执行rabbitmqctl forget_cluster_node -offline B时,RabbitMQ会mock一个节点代表A,执行forget_cluster_node命令将B提出cluster,然后A就能正常启动了。最后将新的slave节点加入A即可重新恢复镜像队列
场景5:A先停,B后停,且A和B均无法恢复,但是能得到A或B的磁盘文件
这个场景更加难以处理。将A或B的数据库文件($RabbitMQ_HOME/var/lib目录中)copy至新节点C的目录下,再将C的hostname改成A或者B的hostname。如果copy过来的是A节点磁盘文件,按场景4处理,如果拷贝过来的是B节点的磁盘文件,按场景3处理。最后将新的slave节点加入C即可重新恢复镜像队列。
场景6:A先停,B后停,且A和B均无法恢复,且无法得到A和B的磁盘文件
无解。
补充:
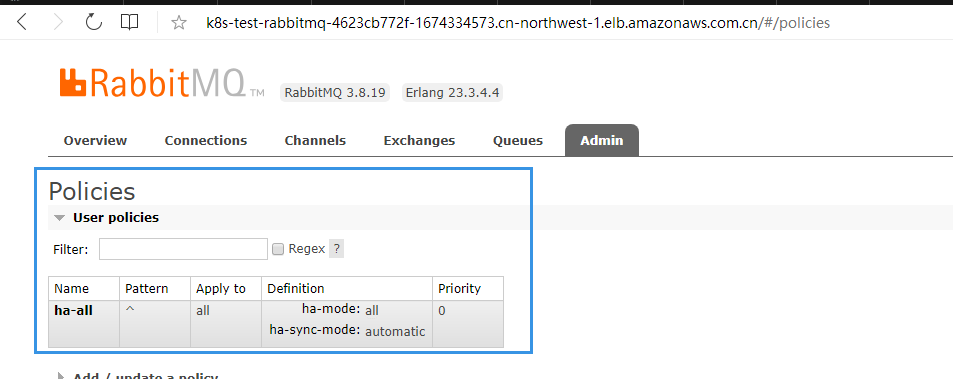
rabbitmqctl设置镜像模式
# 进入pod
kubectl exec -it -n test rabbitmq-0 -- bash
# 列出策略(尚未设置镜像模式)
rabbitmqctl list_policies
# 设置镜像模式
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all" , "ha-sync-mode":"automatic"}'
# 再次列出策略
rabbitmqctl list_policies

 Asynq任务框架
Asynq任务框架 MCP智能体开发实战
MCP智能体开发实战 WEB架构
WEB架构 安全监控体系
安全监控体系