
穷人没办法,为租房而奔波,找房实在太难,数据爬下来用EXCEL分析,过滤无效信息,有需要拿去

import requests
import bs4
import json
import time
import os
from lxml import etree
class spider(object):
def __init__(self):
self.url = "https://sh.zu.anjuke.com/?from=navigation"
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
def get_cities(self):
response = requests.get(self.url, headers=self.headers, timeout=30).text
html = etree.HTML(response)
city_list = html.xpath('//div[@id="city_list"]//dd/a')
cities = {}
for item in city_list:
city_url = item.xpath('./@href')[0]
city_name = item.xpath('./@title')[0]
cities[city_name] = city_url
if not os.path.exists('./data/' + city_name):
os.makedirs('./data/' + city_name)
else:
pass
return cities
def search_addrs(self, url):
response = requests.get(url, headers=self.headers, timeout=20).text
html = etree.HTML(response)
addrs = html.xpath('//div[@class="sub-items sub-level1"]//a')
address = {}
for item in addrs[1:-2]:
addrs_name = item.xpath('./text()')[0]
addrs_url = item.xpath('./@href')[0]
address[addrs_name] = addrs_url
return address
def search_house(self, address_url):
response = requests.get(address_url, headers=self.headers, timeout=20).text
html = etree.HTML(response)
house_list = html.xpath('//div[@id ="list-content"]/div')
for item in house_list[2:]:
house_url = item.xpath('./a/@href')
house_img = item.xpath('./a/img/@src')
house_name = item.xpath('./div[@class="zu-info"]/h3/a/b/text()')
house_addrs = item.xpath('./div[@class="zu-info"]/address/a/text()')
house_price = item.xpath('./div[@class="zu-side"]//b/text()')
print(house_addrs, house_img, house_name, house_price, house_url)
if __name__ == '__main__':
anjuke = spider()
# cities = anjuke.get_cities()
# for city_name in cities.keys():
print('正在爬取')
# url = "https://sh.zu.anjuke.com/?from=navigation"
# address = anjuke.search_addrs(url)
# for addrs_name in address:
i = 0
for page in range(50):
address_url = 'https://sh.zu.anjuke.com/fangyuan/qingpu/x1-p' + str(page)
anjuke.search_house(address_url)
i += 1
if i % 10 == 0:
time.sleep(60)


 Asynq任务框架
Asynq任务框架 MCP智能体开发实战
MCP智能体开发实战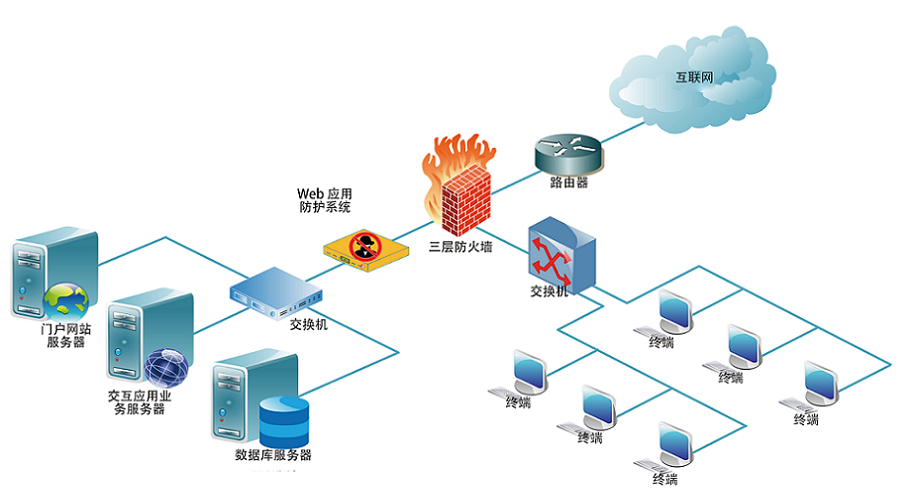 WEB架构
WEB架构 安全监控体系
安全监控体系



