介绍
有关node_exporter参照:
https://github.com/prometheus/node_exporter
主机内存不足
告警条件:节点内存已满(剩余 < 10%)
- alert: HostOutOfMemory
expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 10
for: 2m
labels:
severity: warning
annotations:
summary: Host out of memory (instance {{ $labels.instance }})
description: "节点内存已满 (< 10%)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
内存压力下的主机内存
节点内存压力大。重大页面错误率高
- alert: HostMemoryUnderMemoryPressure
expr: rate(node_vmstat_pgmajfault[1m]) > 1000
for: 2m
labels:
severity: warning
annotations:
summary: Host memory under memory pressure (instance {{ $labels.instance }})
description: "The node is under heavy memory pressure. High rate of major page faults\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机异常的网络吞吐量
主机网络接口接收数据繁忙(> 100 MB/s)
- alert: HostUnusualNetworkThroughputIn
expr: sum by (instance) (rate(node_network_receive_bytes_total[2m])) / 1024 / 1024 > 100
for: 5m
labels:
severity: warning
annotations:
summary: Host unusual network throughput in (instance {{ $labels.instance }})
description: "Host network interfaces are probably receiving too much data (> 100 MB/s)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机异常网络吞吐量输出
主机网络接口可能发送太多数据(> 100 MB/s)
- alert: HostUnusualNetworkThroughputOut
expr: sum by (instance) (rate(node_network_transmit_bytes_total[2m])) / 1024 / 1024 > 100
for: 5m
labels:
severity: warning
annotations:
summary: Host unusual network throughput out (instance {{ $labels.instance }})
description: "Host network interfaces are probably sending too much data (> 100 MB/s)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机异常磁盘读取率
磁盘可能正在读取太多数据(> 50 MB/s)
- alert: HostUnusualDiskReadRate
expr: sum by (instance) (rate(node_disk_read_bytes_total[2m])) / 1024 / 1024 > 50
for: 5m
labels:
severity: warning
annotations:
summary: Host unusual disk read rate (instance {{ $labels.instance }})
description: "Disk is probably reading too much data (> 50 MB/s)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机异常磁盘写入率
磁盘可能正在写入太多数据(> 50 MB/s)
- alert: HostUnusualDiskWriteRate
expr: sum by (instance) (rate(node_disk_written_bytes_total[2m])) / 1024 / 1024 > 50
for: 2m
labels:
severity: warning
annotations:
summary: Host unusual disk write rate (instance {{ $labels.instance }})
description: "Disk is probably writing too much data (> 50 MB/s)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机磁盘空间不足
磁盘几乎已满(剩余 < 10%)
# Please add ignored mountpoints in node_exporter parameters like
# "--collector.filesystem.ignored-mount-points=^/(sys|proc|dev|run)($|/)".
# Same rule using "node_filesystem_free_bytes" will fire when disk fills for non-root users.
- alert: HostOutOfDiskSpace
expr: (node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 10 and ON (instance, device, mountpoint) node_filesystem_readonly == 0
for: 2m
labels:
severity: warning
annotations:
summary: Host out of disk space (instance {{ $labels.instance }})
description: "Disk is almost full (< 10% left)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机盘将在 24 小时内填满
预计文件系统将在未来 24 小时内以当前写入速率耗尽空间
# Please add ignored mountpoints in node_exporter parameters like
# "--collector.filesystem.ignored-mount-points=^/(sys|proc|dev|run)($|/)".
# Same rule using "node_filesystem_free_bytes" will fire when disk fills for non-root users.
- alert: HostDiskWillFillIn24Hours
expr: (node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 10 and ON (instance, device, mountpoint) predict_linear(node_filesystem_avail_bytes{fstype!~"tmpfs"}[1h], 24 * 3600) < 0 and ON (instance, device, mountpoint) node_filesystem_readonly == 0
for: 2m
labels:
severity: warning
annotations:
summary: Host disk will fill in 24 hours (instance {{ $labels.instance }})
description: "Filesystem is predicted to run out of space within the next 24 hours at current write rate\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机 inode 不足
磁盘几乎用完了可用的 inode(剩余不到 10%)
- alert: HostOutOfInodes
expr: node_filesystem_files_free{mountpoint ="/rootfs"} / node_filesystem_files{mountpoint="/rootfs"} * 100 < 10 and ON (instance, device, mountpoint) node_filesystem_readonly{mountpoint="/rootfs"} == 0
for: 2m
labels:
severity: warning
annotations:
summary: Host out of inodes (instance {{ $labels.instance }})
description: "Disk is almost running out of available inodes (< 10% left)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机 inode 将在 24 小时内填写
预计文件系统将在未来 24 小时内以当前写入速率耗尽 inode
- alert: HostInodesWillFillIn24Hours
expr: node_filesystem_files_free{mountpoint ="/rootfs"} / node_filesystem_files{mountpoint="/rootfs"} * 100 < 10 and predict_linear(node_filesystem_files_free{mountpoint="/rootfs"}[1h], 24 * 3600) < 0 and ON (instance, device, mountpoint) node_filesystem_readonly{mountpoint="/rootfs"} == 0
for: 2m
labels:
severity: warning
annotations:
summary: Host inodes will fill in 24 hours (instance {{ $labels.instance }})
description: "Filesystem is predicted to run out of inodes within the next 24 hours at current write rate\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机异常磁盘读取延迟
磁盘延迟正在增长(读取操作 > 100 毫秒)
- alert: HostUnusualDiskReadLatency
expr: rate(node_disk_read_time_seconds_total[1m]) / rate(node_disk_reads_completed_total[1m]) > 0.1 and rate(node_disk_reads_completed_total[1m]) > 0
for: 2m
labels:
severity: warning
annotations:
summary: Host unusual disk read latency (instance {{ $labels.instance }})
description: "Disk latency is growing (read operations > 100ms)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机异常磁盘写入延迟
磁盘延迟正在增长(写入操作 > 100 毫秒)
- alert: HostUnusualDiskWriteLatency
expr: rate(node_disk_write_time_seconds_total[1m]) / rate(node_disk_writes_completed_total[1m]) > 0.1 and rate(node_disk_writes_completed_total[1m]) > 0
for: 2m
labels:
severity: warning
annotations:
summary: Host unusual disk write latency (instance {{ $labels.instance }})
description: "Disk latency is growing (write operations > 100ms)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机高 CPU 负载
CPU 负载 > 80%
- alert: HostHighCpuLoad
expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) > 80
for: 0m
labels:
severity: warning
annotations:
summary: Host high CPU load (instance {{ $labels.instance }})
description: "CPU load is > 80%\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机 CPU 窃取嘈杂的邻居
CPU 窃取率 > 10%。嘈杂的邻居正在扼杀 VM 性能,或者 Spot 实例可能已失去信用。
Steal 值比较高的话,你需要向主机供应商申请扩容虚拟机。服务器上的另一个虚拟机可能拥有更大更多的 CPU 时间片,你可能需要申请升级以与之竞争。另外,高 steal 值可能意味着主机供应商在服务器上过量地出售虚拟机。如果升级了虚拟机, steal 值还是不降的话,你应该寻找另一家服务供应商。
- alert: HostCpuStealNoisyNeighbor
expr: avg by(instance) (rate(node_cpu_seconds_total{mode="steal"}[5m])) * 100 > 10
for: 0m
labels:
severity: warning
annotations:
summary: Host CPU steal noisy neighbor (instance {{ $labels.instance }})
description: "CPU steal is > 10%. A noisy neighbor is killing VM performances or a spot instance may be out of credit.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机上下文切换
节点上的上下文切换正在增长(> 1000 / s)
# 1000 context switches is an arbitrary number.
# Alert threshold depends on nature of application.
# Please read: https://github.com/samber/awesome-prometheus-alerts/issues/58
- alert: HostContextSwitching
expr: (rate(node_context_switches_total[5m])) / (count without(cpu, mode) (node_cpu_seconds_total{mode="idle"})) > 1000
for: 0m
labels:
severity: warning
annotations:
summary: Host context switching (instance {{ $labels.instance }})
description: "Context switching is growing on node (> 1000 / s)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机swap已满
swap已满 (>80%)
- alert: HostSwapIsFillingUp
expr: (1 - (node_memory_SwapFree_bytes / node_memory_SwapTotal_bytes)) * 100 > 80
for: 2m
labels:
severity: warning
annotations:
summary: Host swap is filling up (instance {{ $labels.instance }})
description: "Swap is filling up (>80%)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机 systemd 服务崩溃
systemd 服务崩溃
- alert: HostSystemdServiceCrashed
expr: node_systemd_unit_state{state="failed"} == 1
for: 0m
labels:
severity: warning
annotations:
summary: Host systemd service crashed (instance {{ $labels.instance }})
description: "systemd service crashed\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机物理组件过热
物理硬件组件过热
- alert: HostPhysicalComponentTooHot
expr: node_hwmon_temp_celsius > 75
for: 5m
labels:
severity: warning
annotations:
summary: Host physical component too hot (instance {{ $labels.instance }})
description: "Physical hardware component too hot\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机节点超温报警
物理节点温度告警触发
- alert: HostNodeOvertemperatureAlarm
expr: node_hwmon_temp_crit_alarm_celsius == 1
for: 0m
labels:
severity: critical
annotations:
summary: Host node overtemperature alarm (instance {{ $labels.instance }})
description: "Physical node temperature alarm triggered\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机 RAID 阵列处于非活动状态
由于一个或多个磁盘故障,RAID 阵列 {{ $labels.device }} 处于降级状态。备用驱动器的数量不足以自动修复问题。
- alert: HostRaidArrayGotInactive
expr: node_md_state{state="inactive"} > 0
for: 0m
labels:
severity: critical
annotations:
summary: Host RAID array got inactive (instance {{ $labels.instance }})
description: "RAID array {{ $labels.device }} is in degraded state due to one or more disks failures. Number of spare drives is insufficient to fix issue automatically.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机 RAID 磁盘故障
{{ $labels.instance }} 上的 RAID 阵列中至少有一个设备失败。数组 {{ $labels.md_device }} 需要注意,可能需要磁盘交换
- alert: HostRaidDiskFailure
expr: node_md_disks{state="failed"} > 0
for: 2m
labels:
severity: warning
annotations:
summary: Host RAID disk failure (instance {{ $labels.instance }})
description: "At least one device in RAID array on {{ $labels.instance }} failed. Array {{ $labels.md_device }} needs attention and possibly a disk swap\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机内核版本偏差
不同的内核版本正在运行
- alert: HostKernelVersionDeviations
expr: count(sum(label_replace(node_uname_info, "kernel", "$1", "release", "([0-9]+.[0-9]+.[0-9]+).*")) by (kernel)) > 1
for: 6h
labels:
severity: warning
annotations:
summary: Host kernel version deviations (instance {{ $labels.instance }})
description: "Different kernel versions are running\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
检测到主机 OOM 终止
检测到 OOM 终止
- alert: HostOomKillDetected
expr: increase(node_vmstat_oom_kill[1m]) > 0
for: 0m
labels:
severity: warning
annotations:
summary: Host OOM kill detected (instance {{ $labels.instance }})
description: "OOM kill detected\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
检测到主机 EDAC 可纠正错误
主机 {{ $labels.instance }} 在过去 5 分钟内出现了 EDAC 报告的 {{ printf "%.0f" $value }} 可纠正内存错误。
- alert: HostEdacCorrectableErrorsDetected
expr: increase(node_edac_correctable_errors_total[1m]) > 0
for: 0m
labels:
severity: info
annotations:
summary: Host EDAC Correctable Errors detected (instance {{ $labels.instance }})
description: "Host {{ $labels.instance }} has had {{ printf \"%.0f\" $value }} correctable memory errors reported by EDAC in the last 5 minutes.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
检测到主机 EDAC 不可纠正错误
主机 {{ $labels.instance }} 在过去 5 分钟内出现了 EDAC 报告的 {{ printf "%.0f" $value }} 不可纠正的内存错误。
- alert: HostEdacUncorrectableErrorsDetected
expr: node_edac_uncorrectable_errors_total > 0
for: 0m
labels:
severity: warning
annotations:
summary: Host EDAC Uncorrectable Errors detected (instance {{ $labels.instance }})
description: "Host {{ $labels.instance }} has had {{ printf \"%.0f\" $value }} uncorrectable memory errors reported by EDAC in the last 5 minutes.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机网络接收错误
主机 {{ $labels.instance }} 接口 {{ $labels.device }} 在过去两分钟内遇到 {{ printf "%.0f" $value }} 接收错误。
- alert: HostNetworkReceiveErrors
expr: rate(node_network_receive_errs_total[2m]) / rate(node_network_receive_packets_total[2m]) > 0.01
for: 2m
labels:
severity: warning
annotations:
summary: Host Network Receive Errors (instance {{ $labels.instance }})
description: "Host {{ $labels.instance }} interface {{ $labels.device }} has encountered {{ printf \"%.0f\" $value }} receive errors in the last two minutes.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机网络传输错误
主机 {{ $labels.instance }} 接口 {{ $labels.device }} 在过去两分钟内遇到 {{ printf "%.0f" $value }} 传输错误。
- alert: HostNetworkTransmitErrors
expr: rate(node_network_transmit_errs_total[2m]) / rate(node_network_transmit_packets_total[2m]) > 0.01
for: 2m
labels:
severity: warning
annotations:
summary: Host Network Transmit Errors (instance {{ $labels.instance }})
description: "Host {{ $labels.instance }} interface {{ $labels.device }} has encountered {{ printf \"%.0f\" $value }} transmit errors in the last two minutes.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机网络接口饱和
“{{ $labels.instance }}”上的网络接口“{{ $labels.device }}”正在过载。
- alert: HostNetworkInterfaceSaturated
expr: (rate(node_network_receive_bytes_total{device!~"^tap.*"}[1m]) + rate(node_network_transmit_bytes_total{device!~"^tap.*"}[1m])) / node_network_speed_bytes{device!~"^tap.*"} > 0.8 < 10000
for: 1m
labels:
severity: warning
annotations:
summary: Host Network Interface Saturated (instance {{ $labels.instance }})
description: "The network interface \"{{ $labels.device }}\" on \"{{ $labels.instance }}\" is getting overloaded.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机网络绑定降级
绑定“{{ $labels.device }}”在“{{ $labels.instance }}”上降级。
- alert: HostNetworkBondDegraded
expr: (node_bonding_active - node_bonding_slaves) != 0
for: 2m
labels:
severity: warning
annotations:
summary: Host Network Bond Degraded (instance {{ $labels.instance }})
description: "Bond \"{{ $labels.device }}\" degraded on \"{{ $labels.instance }}\".\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机连接限制
conntrack的数量接近极限
- alert: HostConntrackLimit
expr: node_nf_conntrack_entries / node_nf_conntrack_entries_limit > 0.8
for: 5m
labels:
severity: warning
annotations:
summary: Host conntrack limit (instance {{ $labels.instance }})
description: "The number of conntrack is approaching limit\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机时钟偏差
检测到时钟偏差。时钟不同步。确保在此主机上正确配置了 NTP。
- alert: HostClockSkew
expr: (node_timex_offset_seconds > 0.05 and deriv(node_timex_offset_seconds[5m]) >= 0) or (node_timex_offset_seconds < -0.05 and deriv(node_timex_offset_seconds[5m]) <= 0)
for: 2m
labels:
severity: warning
annotations:
summary: Host clock skew (instance {{ $labels.instance }})
description: "Clock skew detected. Clock is out of sync. Ensure NTP is configured correctly on this host.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机时钟不同步
时钟不同步。确保在此主机上配置了 NTP。
- alert: HostClockNotSynchronising
expr: min_over_time(node_timex_sync_status[1m]) == 0 and node_timex_maxerror_seconds >= 16
for: 2m
labels:
severity: warning
annotations:
summary: Host clock not synchronising (instance {{ $labels.instance }})
description: "Clock not synchronising. Ensure NTP is configured on this host.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
主机需要重启
{{ $labels.instance }} 需要重新启动。
- alert: HostRequiresReboot
expr: node_reboot_required > 0
for: 4h
labels:
severity: info
annotations:
summary: Host requires reboot (instance {{ $labels.instance }})
description: "{{ $labels.instance }} requires a reboot.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
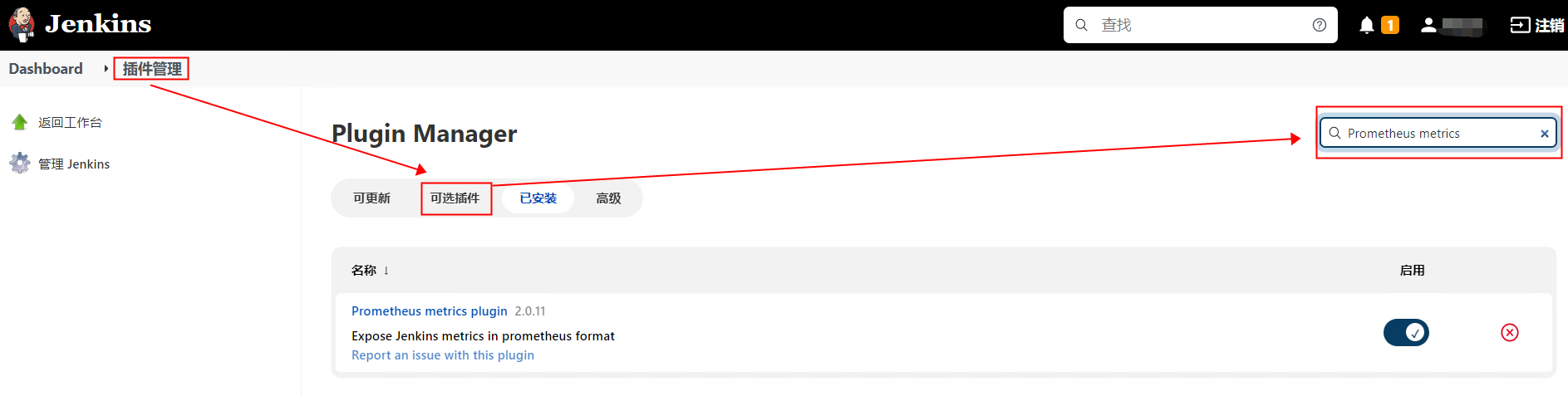


 Asynq任务框架
Asynq任务框架 MCP智能体开发实战
MCP智能体开发实战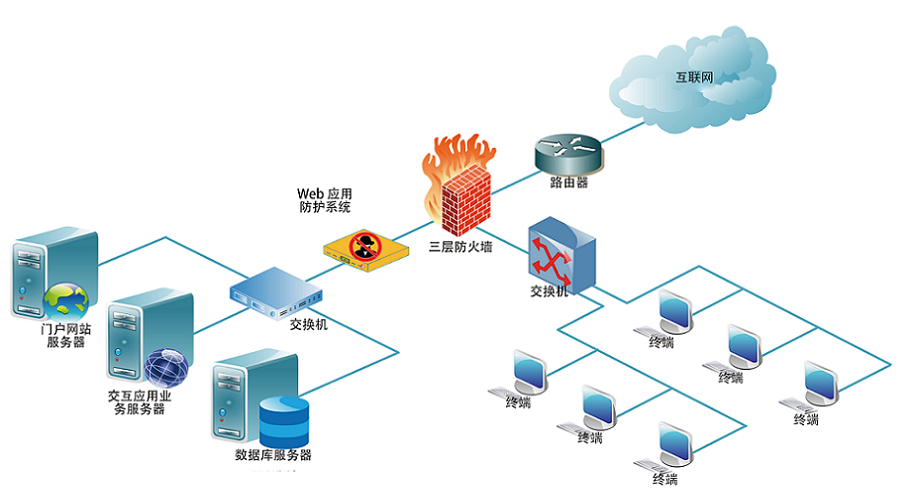 WEB架构
WEB架构 安全监控体系
安全监控体系