参数解释
使用Prometheus配置kubernetes环境中Container的CPU使用率时,会经常遇到CPU使用超出100%,下面就来解释一下
container_spec_cpu_period
当对容器进行CPU限制时,CFS调度的时间窗口,又称容器CPU的时钟周期通常是100,000微秒
container_spec_cpu_quota
是指容器的使用CPU时间周期总量,如果quota设置的是700,000,就代表该容器可用的CPU时间是7*100,000微秒,通常对应kubernetes的resource.cpu.limits的值
container_spec_cpu_share
是指container使用分配主机CPU相对值,比如share设置的是500m,代表窗口启动时向主机节点申请0.5个CPU,也就是50,000微秒,通常对应kubernetes的resource.cpu.requests的值
container_cpu_usage_seconds_total
统计容器的CPU在一秒内消耗使用率,应注意的是该container所有的CORE
container_cpu_system_seconds_total
统计容器内核态在一秒时间内消耗的CPU
container_cpu_user_seconds_total
统计容器用户态在一秒时间内消耗的CPU
参考官方地址
https://docs.signalfx.com/en/latest/integrations/agent/monitors/cadvisor.html
https://github.com/google/cadvisor/blob/master/docs/storage/prometheus.md具体公式
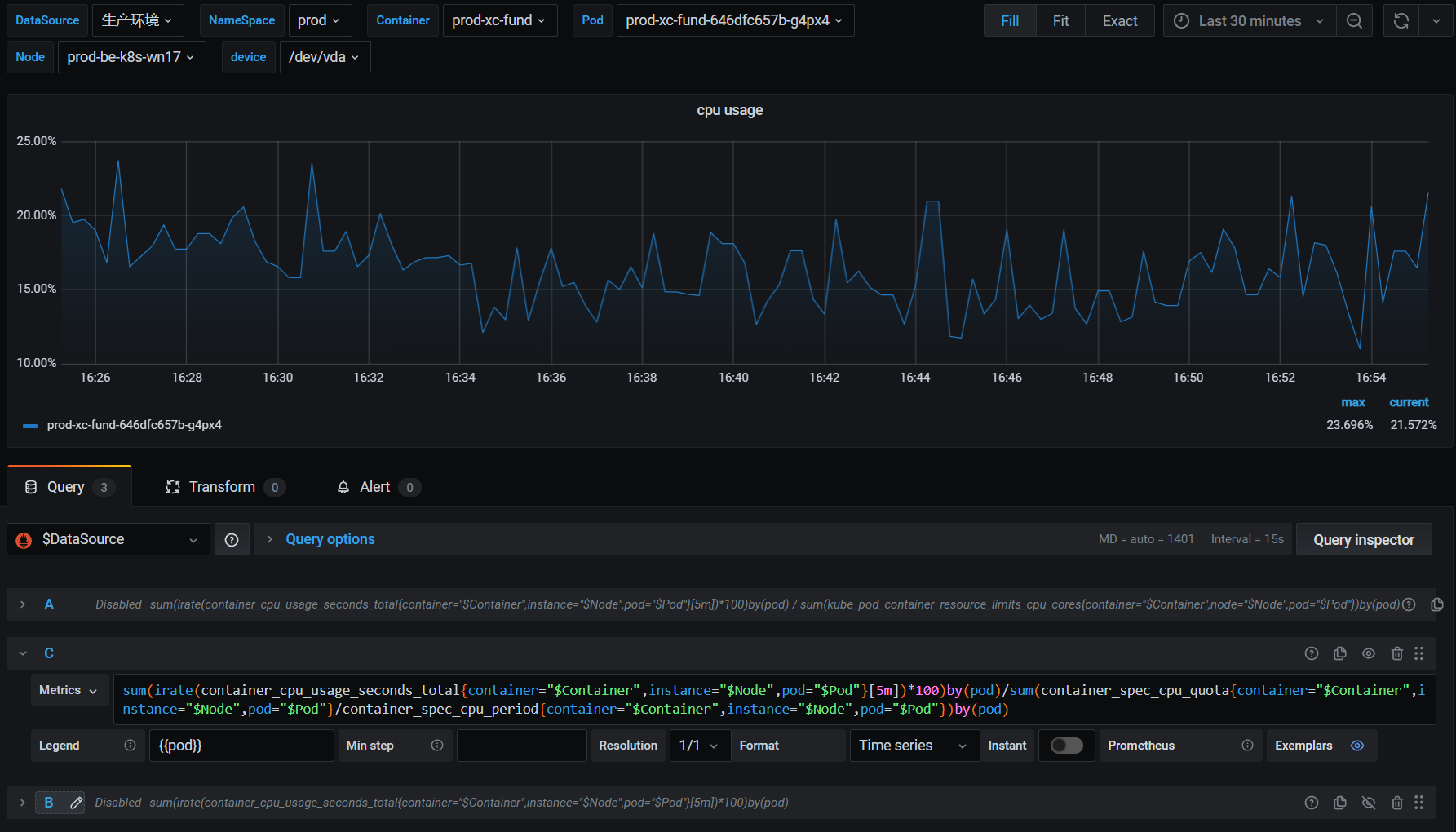
默认如果直接使用container_cpu_usage_seconds_total的话,如下
sum(irate(container_cpu_usage_seconds_total{container="$Container",instance="$Node",pod="$Pod"}[5m])*100)by(pod)默认统计的数据是该容器所有的CORE的平均使用率
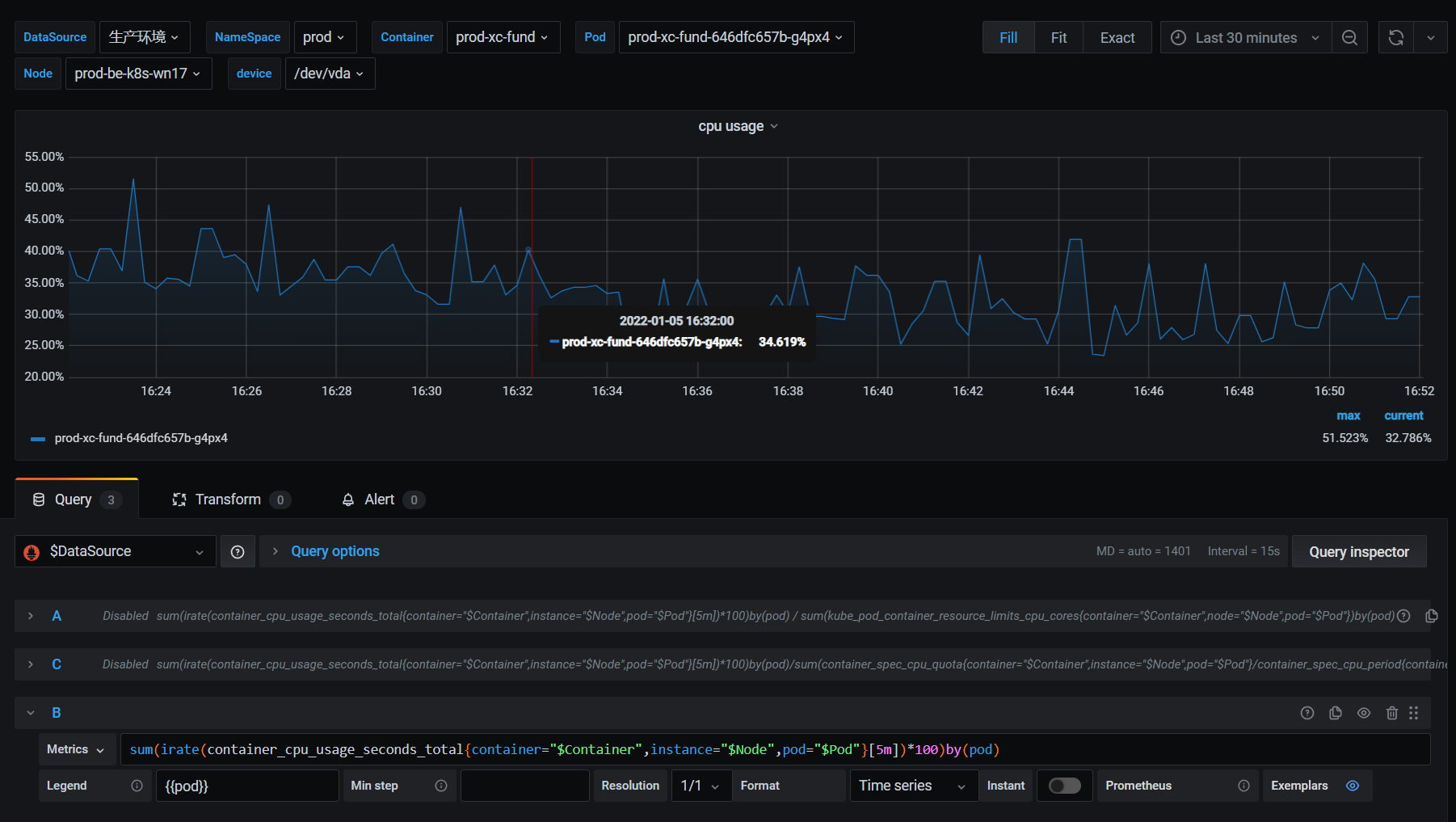
如果要精确计算每个容器的CPU使用率,使用%呈现的形式,如下
sum(irate(container_cpu_usage_seconds_total{container="$Container",instance="$Node",pod="$Pod"}[5m])*100)by(pod)/sum(container_spec_cpu_quota{container="$Container",instance="$Node",pod="$Pod"}/container_spec_cpu_period{container="$Container",instance="$Node",pod="$Pod"})by(pod)其中container_spec_cpu_quota/container_spec_cpu_period,就代表该容器有多少个CORE
参考官方git issue
https://github.com/google/cadvisor/issues/2026#issuecomment-415819667
docker stats
docker stats输出的指标列是如何计算的,如下
首先docker stats是通过Docker API /containers/(id)/stats接口来获得live data stream,再通过docker stats进行整合
在Linux中使用docker stats输出的内存使用率(MEM USAGE),实则该列的计算是不包含Cache的内存
cache usage在 ≤ docker 19.03版本的API接口输出对应的字段是memory_stats.total_inactive_file,而 > docker 19.03的版本对应的字段是memory_stats.cache
docker stats 输出的PIDS一列代表的是该容器创建的进程或线程的数量,threads是Linux kernel中的一个术语,又称 lightweight process & kernel task
如何通过Docker API查看容器资源使用率,如下
<root@PROD-BE-K8S-WN17 ~># curl -s --unix-socket /var/run/docker.sock "http://localhost/v1.40/containers/10f2db238edc/stats" | jq -r
{
"read": "2022-01-05T06:14:47.705943252Z",
"preread": "0001-01-01T00:00:00Z",
"pids_stats": {
"current": 240
},
"blkio_stats": {
"io_service_bytes_recursive": [
{
"major": 253,
"minor": 0,
"op": "Read",
"value": 0
},
{
"major": 253,
"minor": 0,
"op": "Write",
"value": 917504
},
{
"major": 253,
"minor": 0,
"op": "Sync",
"value": 0
},
{
"major": 253,
"minor": 0,
"op": "Async",
"value": 917504
},
{
"major": 253,
"minor": 0,
"op": "Discard",
"value": 0
},
{
"major": 253,
"minor": 0,
"op": "Total",
"value": 917504
}
],
"io_serviced_recursive": [
{
"major": 253,
"minor": 0,
"op": "Read",
"value": 0
},
{
"major": 253,
"minor": 0,
"op": "Write",
"value": 32
},
{
"major": 253,
"minor": 0,
"op": "Sync",
"value": 0
},
{
"major": 253,
"minor": 0,
"op": "Async",
"value": 32
},
{
"major": 253,
"minor": 0,
"op": "Discard",
"value": 0
},
{
"major": 253,
"minor": 0,
"op": "Total",
"value": 32
}
],
"io_queue_recursive": [],
"io_service_time_recursive": [],
"io_wait_time_recursive": [],
"io_merged_recursive": [],
"io_time_recursive": [],
"sectors_recursive": []
},
"num_procs": 0,
"storage_stats": {},
"cpu_stats": {
"cpu_usage": {
"total_usage": 251563853433744,
"percpu_usage": [
22988555937059,
6049382848016,
22411490707722,
5362525449957,
25004835766513,
6165050456944,
27740046633494,
6245013152748,
29404953317631,
5960151933082,
29169053441816,
5894880727311,
25772990860310,
5398581194412,
22856145246881,
5140195759848
],
"usage_in_kernelmode": 30692640000000,
"usage_in_usermode": 213996900000000
},
"system_cpu_usage": 22058735930000000,
"online_cpus": 16,
"throttling_data": {
"periods": 10673334,
"throttled_periods": 1437,
"throttled_time": 109134709435
}
},
"precpu_stats": {
"cpu_usage": {
"total_usage": 0,
"usage_in_kernelmode": 0,
"usage_in_usermode": 0
},
"throttling_data": {
"periods": 0,
"throttled_periods": 0,
"throttled_time": 0
}
},
"memory_stats": {
"usage": 8589447168,
"max_usage": 8589926400,
"stats": {
"active_anon": 0,
"active_file": 260198400,
"cache": 1561460736,
"dirty": 3514368,
"hierarchical_memory_limit": 8589934592,
"hierarchical_memsw_limit": 8589934592,
"inactive_anon": 6947250176,
"inactive_file": 1300377600,
"mapped_file": 0,
"pgfault": 3519153,
"pgmajfault": 0,
"pgpgin": 184508478,
"pgpgout": 184052901,
"rss": 6947373056,
"rss_huge": 6090129408,
"total_active_anon": 0,
"total_active_file": 260198400,
"total_cache": 1561460736,
"total_dirty": 3514368,
"total_inactive_anon": 6947250176,
"total_inactive_file": 1300377600,
"total_mapped_file": 0,
"total_pgfault": 3519153,
"total_pgmajfault": 0,
"total_pgpgin": 184508478,
"total_pgpgout": 184052901,
"total_rss": 6947373056,
"total_rss_huge": 6090129408,
"total_unevictable": 0,
"total_writeback": 0,
"unevictable": 0,
"writeback": 0
},
"limit": 8589934592
},
"name": "/k8s_prod-xc-fund_prod-xc-fund-646dfc657b-g4px4_prod_523dcf9d-6137-4abf-b4ad-bd3999abcf25_0",
"id": "10f2db238edc13f538716952764d6c9751e5519224bcce83b72ea7c876cc0475"如何计算
官方地址
https://docs.docker.com/engine/api/v1.40/#operation/ContainerStats
The precpu_stats is the CPU statistic of the previous read, and is used to calculate the CPU usage percentage. It is not an exact copy of the cpu_stats field.
If either precpu_stats.online_cpus or cpu_stats.online_cpus is nil then for compatibility with older daemons the length of the corresponding cpu_usage.percpu_usage array should be used.
To calculate the values shown by the stats command of the docker cli tool the following formulas can be used:
- used_memory =
memory_stats.usage - memory_stats.stats.cache - available_memory =
memory_stats.limit - Memory usage % =
(used_memory / available_memory) * 100.0 - cpu_delta =
cpu_stats.cpu_usage.total_usage - precpu_stats.cpu_usage.total_usage - system_cpu_delta =
cpu_stats.system_cpu_usage - precpu_stats.system_cpu_usage - number_cpus =
lenght(cpu_stats.cpu_usage.percpu_usage)orcpu_stats.online_cpus - CPU usage % =
(cpu_delta / system_cpu_delta) * number_cpus * 100.0



 Asynq任务框架
Asynq任务框架 MCP智能体开发实战
MCP智能体开发实战 WEB架构
WEB架构 安全监控体系
安全监控体系